
Accurate evaluation of the function 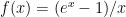
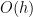
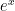
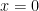
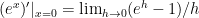



The “usual” accurate method to evaluate 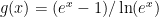
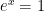
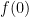
expm1 whose implementation is based on an algorithm due to William Kahan.
Why do 
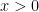
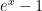
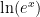
x = 9.000000000000000e-015, using double precision in MATLAB R2009a on a machine running Windows XP with an Intel Core 2 Duo E8400 CPU, the former is 9.103828801926284e-015 and the latter is 9.103828801926243e-015, while in exact arithmetic they are, up to 16 significant digits, 9.000000000000040e-015 and 8.999999999999999e-15, respectively. The ratios, however, are both equal to 1.000000000000004 up to 16 significant digits!
From the title of this post, and the fact that the method just illustrated was referred to as “usual,” it shouldn’t be too hard to expect that another method is to be discussed here. The underlying idea of this other method, due to [KassamTrefethen2005], is the same as the one discussed in Complex Magic, Part 2: Cauchy’s integral formula, only this time Cauchy helps with calculating the function itself, not its derivative,

An elegant heuristic proof of (1), based on a fluid flow interpretation from Mark Levi’s Mathematical Mechanic [Levi2009], can be given by recasting the definition of holomorphicity of the function 
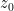
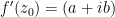
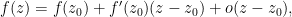
(in other words, namely that there exists a linear approximation to 
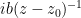

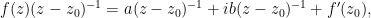
noting that the contributions of these three terms to the contour integral 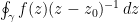
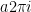
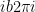
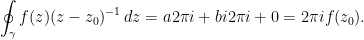
– The word “generating” is important in the above “proof.” The source, vortex, and ideal flow functions arise from treating the complex conjugates of the aforementioned generating functions as vector fields.
– Donald Knuth’s “

With only a slight modification (the highlighted lines) to the diffc of Complex Magic, Part 2 we can get it to work for zeroth derivative (i.e., function evaluation), too.
function [S_M,delta_M] = diffc(f,varargin)
[x0,n,r,M] = deal(0,1,.1,3);
optArgs = {x0,n,r,M};
emptyArgs = cellfun(@isempty,varargin);
[optArgs{~emptyArgs}] = varargin{~emptyArgs};
[x0,n,r,M] = optArgs{:};
f_x0 = f(x0);
[G_M,S_M] = deal(0);
for m = 1:M
if n == 0
mn = M;
mobius_m = 1;
else
mn = m*n;
mobius_m = mobius(m);
end
t = linspace(1/(mn),1,mn);
g = real( f( x0 + r * exp(1i * 2*pi * t) ) );
G_M = max( abs( [G_M f_x0 g] ) );
S_M = S_M + mobius_m * ( mean(g) - f_x0 );
if n == 0, break, end
end
delta_M = eps(G_M) * G_M/S_M;
S_M = factorial(n)/(r^n) * S_M;
Apropos of nothing, note that because linspace(d1,d2,n)‘s implementation outputs [d1+(0:n-2)*(d2-d1)/(floor(n)-1) d2], there is always at least one point, namely d2, returned by linspace, even if n = 0. Also, note that apparently the method MATLAB uses for printing the values of symbolic variables in the Command Window is different from what it uses for double variables, as there is no indentation when symbolic variables are output to the Command Window. Compare x = 1, y = sym(1), z = vpa(1).
f = @(x) (exp(x) - 1)./x; x_0 = 1e-18; x_vpa = vpa(x_0,32); n = 0; r = .5; M = 16; tic, f_vpa = f(x_vpa), toc tic, [f_M,delta_M] = diffc(f,x_0,n,r,M), toc
We see from the output of the above snippet that, using variable precision arithmetic (vpa) with 32 digits, the value of 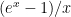
x = 1e-18 is 1.0000000000000000004999535947385 and that on a contour of radius 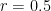

diffc achieves 1.000000000000000 which agrees with the vpa evaluation in all its 16 digits.
The integrand in (1) was written as 
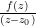
-----BEGIN DIGRESSION-----
Let us digress, a bit and not to the Neverland! According to Gilbert Strang, there are only two functions whose power series one should know by heart: 
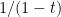
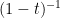
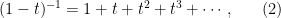
for 

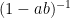
Another place this kind of recasting can yield a unified treatment is in projections. For 


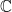
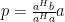
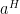

-----END DIGRESSION-----
A similar rationale is behind recasting the integrand in (1) from the usual division to multiplication by the inverse: the latter holds in the more general case when 



![{z_0 = [z_0]_{1\times 1}}](https://s0.wp.com/latex.php?latex=%7Bz_0+%3D+%5Bz_0%5D_%7B1%5Ctimes+1%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Why is the operator 

where 

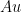


In a stiff system of ODEs two restrictions apply to the time steps a numerical solver can take; one is imposed by stability, dictated by the largest eigenvalue (in magnitude), just as in the case of a single ODE, and the other is imposed by the desired accuracy. The former pushes the time step to be much smaller than is required by the latter and this is a dilemma. A scheme not specially designed to handle stiffness is not aware of these two different time scales, would take very small steps and as a result would take an awfully long time to solve the a stiff problem. It is important to note that this (time) inefficiency is the only problem such a scheme would have; other things being equal, stiffness does not render a nonstiff scheme unstable or divergent. (See Cleve Moler’s “corner” article Stiff Differential Equations and Gilbert Strang’s treasure trove “Introduction to Applied Mathematics” for more details.)
The discussion of ETD here is based on [CoxMatthews2002], which is a very nice read. The underlying idea of ETD schemes is simple: apply the matrix exponential 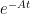

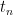


A first order approximation to

where 


![\displaystyle \begin{array}{rcl} a_n & = & e^{Ah}/2u_n + A^{-1} (e^{Ah}/2 - I) N(u_n,t_n),\\ b_n & = & e^{Ah}/2u_n + A^{-1} (e^{Ah}/2 - I) N(a_n,t_n + h/2),\\ c_n & = & e^{Ah}/2a_n + A^{-1} (e^{Ah}/2 - I)(2N(b_n,t_n + h/2) - N(u_n,t_n)),\\ u_{n+1} & = & e^{Ah}u_n + h^{-2} A^{-3}\{ [ -4 - Ah + e^{Ah} ( 4 - 3Ah + (Ah)^2 ) ] N(u_n,t_n)\\ & & {} + 2[ 2 + Ah + e^{Ah} (-2 + Ah) ]( N(a_n,t_n + h/2) + N(b_n,t_n + h/2) )\\ & & {} + [ -4 - 3Ah - (Ah)^2 + e^{Ah}(4 - Ah) ] N(c_n,t_n + h)\}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++a_n+%26+%3D+%26+e%5E%7BAh%7D%2F2u_n+%2B+A%5E%7B-1%7D+%28e%5E%7BAh%7D%2F2+-+I%29+N%28u_n%2Ct_n%29%2C%5C%5C+b_n+%26+%3D+%26+e%5E%7BAh%7D%2F2u_n+%2B+A%5E%7B-1%7D+%28e%5E%7BAh%7D%2F2+-+I%29+N%28a_n%2Ct_n+%2B+h%2F2%29%2C%5C%5C+c_n+%26+%3D+%26+e%5E%7BAh%7D%2F2a_n+%2B+A%5E%7B-1%7D+%28e%5E%7BAh%7D%2F2+-+I%29%282N%28b_n%2Ct_n+%2B+h%2F2%29+-+N%28u_n%2Ct_n%29%29%2C%5C%5C+u_%7Bn%2B1%7D+%26+%3D+%26+e%5E%7BAh%7Du_n+%2B+h%5E%7B-2%7D+A%5E%7B-3%7D%5C%7B+%5B+-4+-+Ah+%2B+e%5E%7BAh%7D+%28+4+-+3Ah+%2B+%28Ah%29%5E2+%29+%5D+N%28u_n%2Ct_n%29%5C%5C+%26+%26+%7B%7D+%2B+2%5B+2+%2B+Ah+%2B+e%5E%7BAh%7D+%28-2+%2B+Ah%29+%5D%28+N%28a_n%2Ct_n+%2B+h%2F2%29+%2B+N%28b_n%2Ct_n+%2B+h%2F2%29+%29%5C%5C+%26+%26+%7B%7D+%2B+%5B+-4+-+3Ah+-+%28Ah%29%5E2+%2B+e%5E%7BAh%7D%284+-+Ah%29+%5D+N%28c_n%2Ct_n+%2B+h%29%5C%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(The terms multiplying powers of 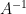
We are now ready to write a simple function fevalc that computes (1) for the general case that
function f_z0 = fevalc(f,varargin)
[z0,r,M] = deal(0,.1,16);
optArgs = {z0,r,M};
emptyArgs = cellfun(@isempty,varargin);
[optArgs{~emptyArgs}] = varargin{~emptyArgs};
[z0,r,M] = optArgs{:};
I = eye(size(z0));
f_z0 = zeros(size(z0));
zs = r * exp( 1i*pi*( ((1:M) - .5 )/M ) );
for j = 1:M
z = zs(j);
zI_z0_inv = inv(z*I - z0);
f_z0 = f_z0 + f(z) * zI_z0_inv * z; %#ok<MINV>
end
f_z0 = real(f_z0)/M;
Note that for the special case when zs = r * exp( 1i*pi*( ((1:M) - .5 )/M ) ); f_z0 = real(mean(f(zs))).
For the sake of demonstration, let us calculate one of the “troubled” terms (or “troublesome,” depending on your view point!), say ![{h^{-2} A^{-3} [-4 - Ah + e^{Ah} ( 4 - 3Ah + (Ah)^2 ) ]}](https://s0.wp.com/latex.php?latex=%7Bh%5E%7B-2%7D+A%5E%7B-3%7D+%5B-4+-+Ah+%2B+e%5E%7BAh%7D+%28+4+-+3Ah+%2B+%28Ah%29%5E2+%29+%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

function ETD4RK_term_eval N = 5; D = cheb(N); h = 1/10; D2 = D^2; D2 = .01*D2(2:N,2:N); Ah = h*D2; f = @(z) ( h*z^(-3) * (-4 - z + exp(z)*(4 - 3*z + z^2) ) ); f_A = f(Ah); f_A_c = fevalc(f,Ah,20,10); function [D,x] = cheb(N) if N == 0, D = 0; x = 1; return, end x = cos(pi*(0:N)/N)'; c = [2; ones(N-1,1); 2].*(-1).^(0:N)'; X = repmat(x,1,N+1); dX = X - X'; D = (c*(1./c)')./(dX + (eye(N+1))); D = D - diag(sum(D,2));
(The border rows and columns are being chopped off from D2 to impose the constant boundary conditions. For more details about the implementation of boundary conditions and how the function cheb generates the Chebyshev differentiation matrix see [Trefethen2000].)
This is 
 |
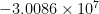 |
 |
|
 |
 |
|
|
| |
|
|
|
| |
|
|
|
This is fevalc
 |
 |
 |
 |
 |
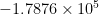 |
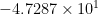 |
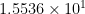 |
| |
|
|
|
| |
|
|
|
Of course, as mentioned before, the calculation in ETD4RK_term_eval is for demonstration only. The “troubled” terms in (5) need not, and in fact should not, be calculated one by one using fevalc, as the inverse matrix 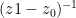

ETD4RK_term_eval can be accounted for by reducing the power of inv is doing cannot be achieved using the backslash operator. Another case in which the inverse matrix itself is needed and cannot be replaced by the backslash operator is calculating the standard errors of the estimates, in an identification problem, based on the inverse of the Fisher information matrix.

